
This is the second part of the two-part series of posts relating to information retrieval by applying predictive coding analysis, and details out the trade-off between Recall and Precision. For part 1 of 2, click here.
To clarify further:
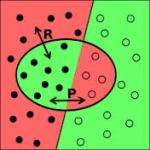
Precision (P) is the fraction of retrieved documents that are relevant, where Precision = (number of relevant items retrieved/number of retrieved items) = P (relevant | retrieved)
Recall (R) is the fraction of relevant documents that are retrieved, where Recall = (number of relevant items retrieved/number of relevant items = P (retrieved | relevant)
Recall and Precision are inversely related. A solid criticism of these two metrics is the aspect of biasness, where certain record may be relevant to a person, may not be relevant to another.
So how do you gain optimal values for Recall and Precision in a TAR platform?
Let’s consider a simple scenario:
• A database contains 80 records on a particular topic
• A search was conducted on that topic and 60 records were retrieved.
• Of the 60 records retrieved, 45 were relevant.
Calculate the precision and recall.
Solution:
Using the designations above:
• A = Number of relevant records retrieved,
• B = Number of relevant records not retrieved, and
• C = Number of irrelevant records retrieved.
In this example A = 45, B = 35 (80-45) and C = 15 (60-45).
Recall = (45 / (45 + 35)) * 100% => 45/80 * 100% = 56%
Precision = (45 / (45 + 15)) * 100% => 45/60 * 100% = 75%
So, essentially – the optimal result – high Recall with high Precision is difficult to achieve.
According to Cambridge University Press:
“The advantage of having the two numbers for precision and recall is that one is more important than the other in many circumstances. Typical web surfers would like every result on the first page to be relevant (high precision) but have not the slightest interest in knowing let alone looking at every document that is relevant. In contrast, various professional searchers such as paralegals and intelligence analysts are very concerned with trying to get as high recall as possible, and will tolerate fairly low precision results in order to get it. Individuals searching their hard disks are also often interested in high recall searches. Nevertheless, the two quantities clearly trade off against one another: you can always get a recall of 1 (but very low precision) by retrieving all documents for all queries! Recall is a non-decreasing function of the number of documents retrieved. On the other hand, in a good system, precision usually decreases as the number of documents retrieved is increased”
![]()
e-Discovery | cloud computing
New Jersey, USA | Lahore, PAK | Dubai, UAE
www.claydesk.com
(855) – 833 – 7775
(703) – 646 – 3043




Recall and Precision




